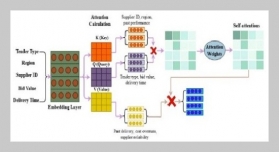
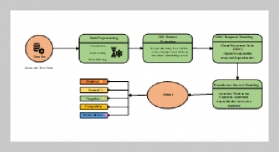
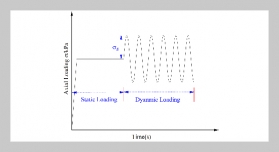
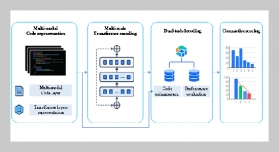
- [1] H. Xu, H. Liu, X. Chen, L. Wang, K. Jin, S. Hou, and Z. Li, (2025) “Elastic Scaling Method for Multi-tenant Databases Based on Hybrid Workload Prediction Model" International Journal of Software and Informatics 15(01): 69–86. DOI: 10.21655/ijsi.1673-7288.00346.
- [2] A. Verbitski, A. Gupta, D. Saha, M. Brahmadesam, K. Gupta, R. Mittal, S. Krishnamurthy, S. Maurice, T. Kharatishvili, and X. Bao. “Amazon aurora: Design considerations for high throughput cloud-native re lational databases”. In: Proceedings of the 2017 ACM International Conference on Management of Data. 2017, 1041–1052. DOI: 10.1145/3035918.3056101.
- [3] W. Cao, Y. Zhang, X. Yang, F. Li, S. Wang, Q. Hu, X. Cheng, Z. Chen, Z. Liu, J. Fang, et al. “Polardb serverless: A cloud native database for disaggregated data centers”. In: Proceedings of the 2021 International Conference on Management of Data. 2021, 2477–2489. DOI: 10.1145/3448016.3457560.
- [4] J. C. Corbett, J. Dean, M. Epstein, A. Fikes, C. Frost, J. J. Furman, S. Ghemawat, A. Gubarev, C. Heiser, P. Hochschild, et al., (2013) “Spanner: Google’s globally distributed database" ACM Transactions on Computer Systems (TOCS) 31(3): 1–22. DOI: 10.1145/2491245.
- [5] P. Antonopoulos, A. Budovski, C. Diaconu, A. Hernandez Saenz, J. Hu, H. Kodavalla, D. Kossmann, S. Lingam, U. F. Minhas, N. Prakash, et al. “Socrates: The newsqlserver in the cloud”. In: Proceedings of the 2019 International Conference on Management of Data. 2019, 1743–1756. DOI: 10.1145/3299869.3314047.
- [6] S. Salza and M. Terranova. “Workload modeling for relational database systems”. In: Database Machines: Fourth International Workshop Grand Bahama Island, March 1985. Springer. 1985, 233–255. DOI: 10.1007/978-1-4612-5144-6_12.
- [7] T.-T. Nguyen, Y.-J. Yeom, T. Kim, D.-H. Park, and S. Kim, (2020) “Horizontal pod autoscaling in kubernetes for elastic container orchestration" Sensors 20(16): 4621. DOI: 10.3390/s20164621.
- [8] Y. Zhu, J. Liu, M. Guo, Y. Bao, W. Ma, Z. Liu, K. Song, and Y. Yang. “Best config: tapping the performance potential of systems via automatic configuration tun ing”. In: Proceedings of the 2017 symposium on cloud computing. 2017, 338–350. DOI: 10.1145/3127479. 3128605.
- [9] L. Ma, D. Van Aken, A. Hefny, G. Mezerhane, A. Pavlo, and G. J. Gordon. “Query-based workload forecasting for self-driving database management systems”. In: Proceedings of the 2018 International Con ference on Management of Data. 2018, 631–645. DOI: 10.1145/3183713.3196908.
- [10] A. Zafeiropoulos, E. Fotopoulou, N. Filinis, and S. Papavassiliou, (2022) “Reinforcement learning-assisted autoscaling mechanisms for serverless computing plat forms" Simulation Modelling Practice and Theory 116: 102461. DOI: 10.1016/j.simpat.2021.102461.
- [11] J. Zhang, K. Zhou, G. Li, Y. Liu, M. Xie, B. Cheng, and J. Xing, (2021) “CDBTune+: An efficient deep reinforcement learning-based automatic cloud database tuning system" The VLDB Journal 30(6): 959–987. DOI: 10.1007/s00778-021-00670-9.
- [12] B. Mozafari, C. Curino, A. Jindal, and S. Mad den. “Performance and resource modeling in highly concurrent OLTP workloads”. In: Proceedings of the 2013 acmsigmod international conference on manage ment of data. 2013, 301–312. DOI: 10.1145/2463676.2467800y.
- [13] A. Mahgoub, P. Wood, A. Medoff, S. Mitra, F. Meyer, S. Chaterji, and S. Bagchi. “{SOPHIA}: Online re configuration of clustered {NoSQL} databases for {Time-Varying} workloads”. In: 2019 USENIX Annual Technical Conference (USENIX ATC 19). 2019, 223 240. DOI: 10.5555/3358807.3358827.
- [14] J. Wang, T. Li, A. Wang, X. Liu, L. Chen, J. Chen, J. Liu, J. Wu, F. Li, and Y. Gao, (2023) “Real-time workload pattern analysis for large-scale cloud databases" arXiv preprint arXiv:2307.02626: DOI: 10.48550/arXiv.2307. 02626.
- [15] Z. Chen, J. Hu, G. Min, A. Y. Zomaya, and T. El Ghazawi, (2019) “Towards accurate prediction for high dimensional and highly-variable cloud workloads with deep learning" IEEE Transactions on Parallel and Dis tributed Systems 31(4): 923–934. DOI: 10.1109/TPDS. 2019.2953745.
- [16] J. Bi, H. Yuan, and M. Zhou, (2019) “Temporal pre diction of multiapplication consolidated workloads in dis tributed clouds" IEEE Transactions on Automation Science and Engineering 16(4): 1763–1773. DOI: 10.1109/TASE.2019.2895801.
- [17] O. Poppe, Q. Guo, W. Lang, P. Arora, M. Oslake, S. Xu, and A. Kalhan, (2022) “Moneyball: proactive auto-scaling in Microsoft Azure SQL database serverless" Proceedings of the VLDB Endowment 15(6): 1279–1287. DOI: 10.14778/3514061.3514073.
- [18] P. Padala, K.-Y. Hou, K. G. Shin, X. Zhu, M. Uysal, Z. Wang, S. Singhal, and A. Merchant. “Automated control of multiple virtualized resources”. In: Proceedings of the 4th ACM European conference on Computer systems. 2009, 13–26. DOI: 10.1145/1519065.1519068.
- [19] H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang. “Informer: Beyond efficient trans former for long sequence time-series forecasting”. In: Proceedings of the AAAI conference on artificial intel ligence. 35. 12. 2021, 11106–11115. DOI: 10.1609/aaai.v35i12.17325.
- [20] H. Wu, J. Xu, J. Wang, and M. Long, (2021) “Auto former: Decomposition transformers with auto-correlation for long-term series forecasting" Advances in neural in formation processing systems 34: 22419–22430. DOI: 10.48550/arXiv.2106.13008.
- [21] T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin. “Fed former: Frequency enhanced decomposed transformer for long-term series forecasting”. In: International conference on machine learning. PMLR. 2022, 27268–27286. DOI: 10.48550/arXiv.2201.12740.
- [22] Y. Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, (2023) “itransformer: Inverted transformers are effective for time series forecasting" arXiv preprint arXiv:2310.06625: DOI: 10.48550/arXiv.2310.06625.
- [23] A. Zeng, M. Chen, L. Zhang, and Q. Xu. “Are trans formers effective for time series forecasting?” In: Proceedings of the AAAI conference on artificial intelligence. 37. 9. 2023, 11121–11128. DOI: 10.1609/aaai.v37i9. 26317.
- [24] S.-A. Chen, C.-L. Li, N. Yoder, S. O. Arik, and T. Pfister, (2023) “Tsmixer: An all-mlp architecture for time series forecasting" arXiv preprint arXiv:2303.06053: DOI: 10.48550/arXiv.2303.06053.
- [25] C. Challu, K. G. Olivares, B. N. Oreshkin, F. G. Ramirez, M. M. Canseco, and A. Dubrawski. “Nhits: Neural hierarchical interpolation for time series fore casting”. In: Proceedings of the AAAI conference on arti ficial intelligence. 37. 6. 2023, 6989–6997. DOI: 10.1609/ aaai.v37i6.25854.
- [26] D. Campos, M. Zhang, B. Yang, T. Kieu, C. Guo, and C. S. Jensen, (2023) “LightTS: Lightweight time series classification with adaptive ensemble distillation" Proceedings of the ACM on Management of Data 1(2): 1–27. DOI: 10.1145/3589316.
- [27] K. Yi, Q. Zhang, W. Fan, S. Wang, P. Wang, H. He, N. An, D. Lian, L. Cao, and Z. Niu, (2023) “Frequency domain mlps are more effective learners in time series forecasting" Advances in Neural Information Pro cessing Systems 36: 76656–76679. DOI: 10.48550/arXiv.2311.06184.
- [28] Q. Huang, L. Shen, R. Zhang, J. Cheng, S. Ding, Z. Zhou, and Y. Wang, (2024) “Hdmixer: Hierarchical de pendency with extendable patch for multivariate time series forecasting" 38(11): 12608–12616. DOI: 10.1609/aaai.v38i11.29155.
- [29] Y. Zhao, Z. Ma, T. Zhou, M. Ye, L. Sun, and Y. Qian, (2023) “Gcformer: an efficient solution for accurate and scalable long-term multivariate time series forecasting": 3464–3473. DOI: 10.1145/3583780.3615136.
- [30] Y. Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, (2022) “A time series is worth 64 words: Long-term forecasting with transformers" arXiv preprint arXiv:2211.14730: DOI: 10.48550/arXiv.2211.14730.